It's hard to believe River UI is almost a year old! 🎂 To celebrate, we've been keeping the changelogs full with big new features across River and its UI.
Job list filters
Since its launch, one of the most requested UI features has been the ability to filter the job list to help find the job you're looking for. As of today, you can now filter jobs by kind, queue, ID, and priority across all job states:
The job filters work well on desktop or mobile, and with mouse, touch, or keyboard navigation. Additional filtering by job args and metadata will come in a future update.
These filters are flexible and may not always result in efficient queries using River's standard indices, so users with high job counts or constrained databases should be mindful of the potential performance impact.
Job logs and unified attempts view
Many users have also asked for the ability to record and store logs to be associated with their River jobs (separate from the job's output, another recent feature addition). We recently added a riverlog package that makes this easy to do using an embedded slog.Logger that stores the logs in the job's metadata when its result is saved.
riverClient, err := river.NewClient(riverpgxv5.New(dbPool), &river.Config{ Middleware: []rivertype.Middleware{ riverlog.NewMiddleware(func(w io.Writer) slog.Handler { return &slogutil.SlogMessageOnlyHandler{Out: w} }, nil), },})func (w *LoggingWorker) Work(ctx context.Context, job *river.Job[LoggingArgs]) error { riverlog.Logger(ctx).InfoContext(ctx, "Logged from worker") return nil}Now, this feature is also available in River UI to display the logs recorded on each attempt. We also redesigned this section of the job detail page to present a unified view of all attempts, including any errors or logs:
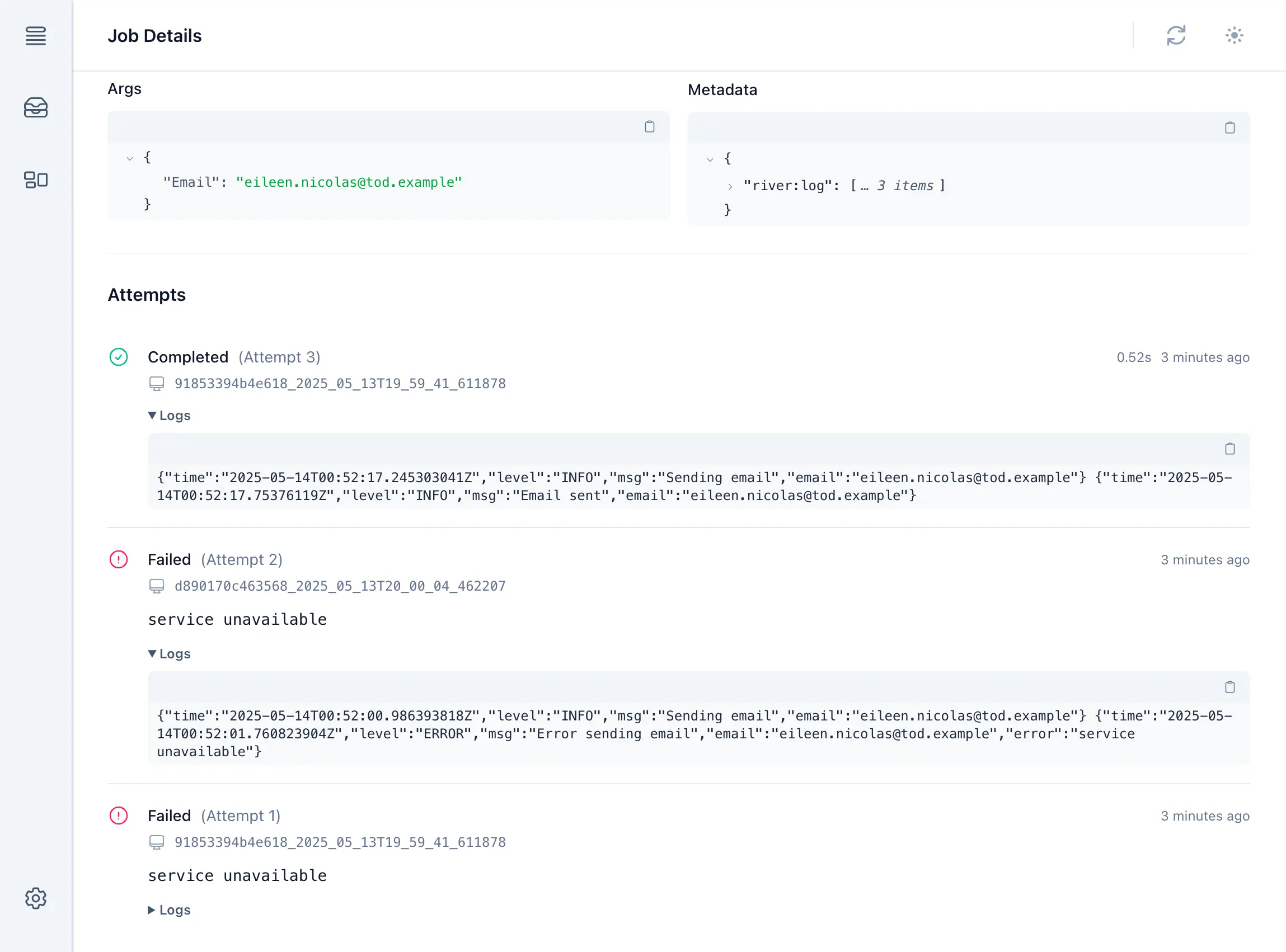
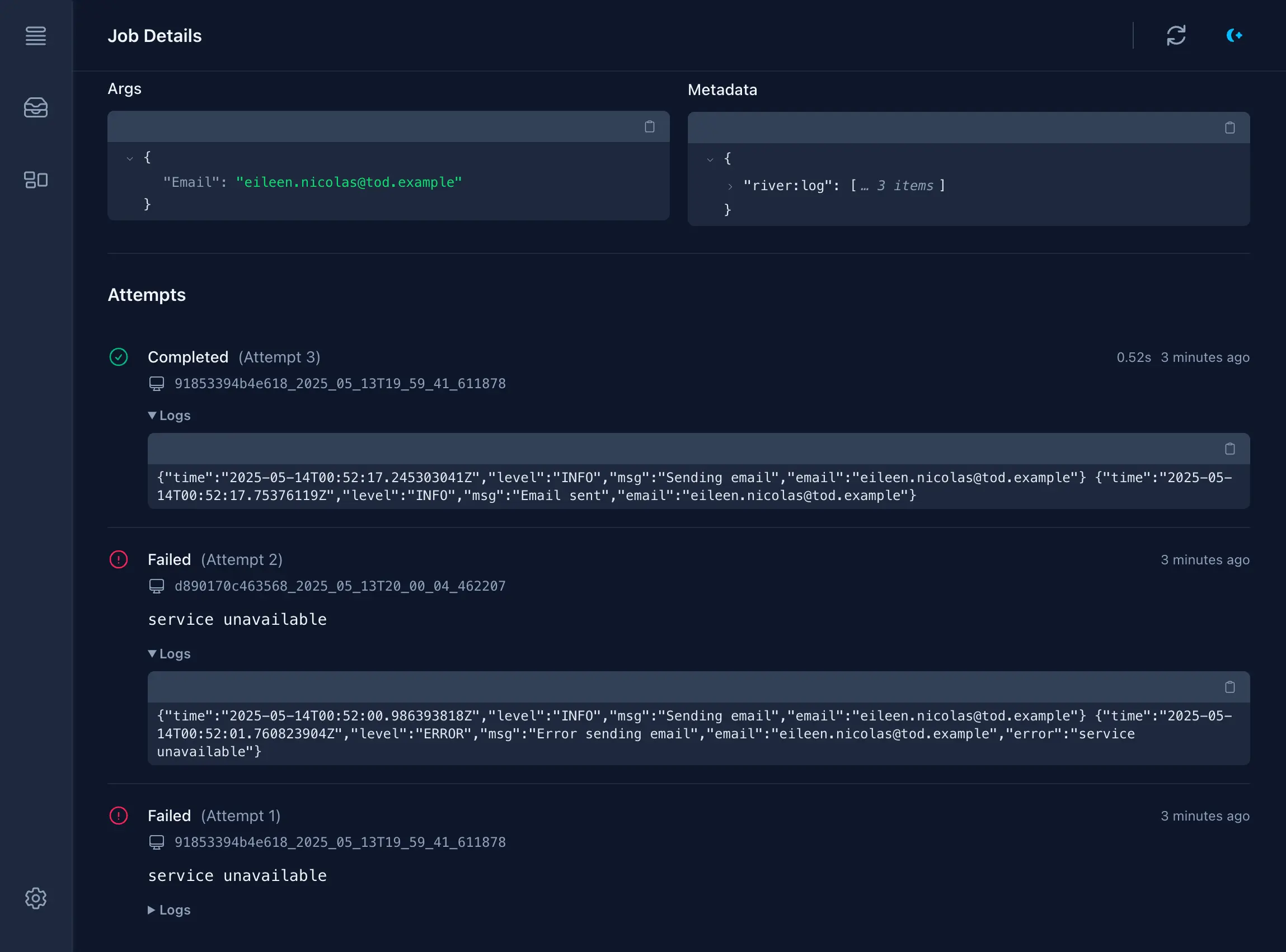
This UI should make it easier to understand the job's history and debug issues. It's already given us some ideas for other metadata we could record and display such as per-attempt timing info.
Full support for alternative Postgres schemas
River has always had some support for alternate schemas in Postgres, but it relied on specifying the search_path in the connection string. This approach was not reliable for pgBouncer users and also made things more complicated for users whose apps use multiple schemas at once.
To fix this, there's a new Config.Schema option that lets a non-default schema be injected explicitly into a River client that'll be used for all database operations, taking precedence over any configured search_path. This should be fully compatible with connection poolers—pgBouncer users rejoice!
riverClient, err := river.NewClient(myDriver, &river.Config{ Schema: "my_schema", // ...})Improved lib/pq compatibility
While River added database/sql support awhile ago, this only worked well for those using pgx through a database/sql wrapper. For those using lib/pq, this never really worked correctly due to several query incompatibilities with that driver. Even though lib/pq is somewhat unmaintained, many apps are still using it and would benefit from better support.
To fix this reliably, we improved River's test suite to run comprehensive database/sql tests with both pgx and lib/pq to ensure compatibility. As part of this work, we also fixed a number of issues and added missing features. It turns out there were a bunch of little fixes required—but those are now all in place and lib/pq users should have a much better experience.
Job kind aliases
If you've ever had to rename a job cleanly in production, you've had to deal with a multi-step process of redundant workers to let old jobs clear out before removing the old kind. To make this a little less painful, River now supports job kind aliases, letting you define one or more additional names for a job kind that will be treated as the same kind when working the job. They're defined through an optional func KindAliases() []string interface on your job struct:
func (j *MyJob) Kind() string { return "my_job_v2"}
func (j *MyJob) KindAliases() []string { return []string{"my_job_v0", "my_job_v1"}}Other UI improvements
Some users have jobs whose args are particularly large, complex, or ugly (think serialized protobufs). To avoid making your eyes bleed, there UI now has an option to hide job args on the list view by default. The default is configurable as a backend setting, but can be overridden for an individual user with the new settings page.
Speaking of complex arg and metadata payloads, we've switched the job detail page to use a new collapsible JSON viewer, including one-click copy for the raw JSON data:


This should make it easier to work with jobs that have large or complex payloads and will avoid pushing the attempts list too far down the page for such cases.
Made possible by River Pro customers
It sure feels like River's development pace has picked up lately 😅 In addition to all the new stuff above, we recently launched global concurrency limits and encrypted jobs for Pro customers.
If you haven't checked out River Pro yet, now's a great time—and thank you to all the Pro customers who've been supporting the project so far!