River clients can be configured with logging middleware that makes a logger available in Work context. Logs emitted during work are stored to job rows as metadata and made available in River UI.
Logs in the database
Large software installations will have access to industrial-strength tooling like Splunk for searching and aggregating logs, but although good, it's often expensive and requires dedicated personnel to operate. River's job-persisted logging is a lightweight out-of-the-box alternative, providing a compromise between observability and ease/cost of installation.
riverlog makes a logger available in the context of Work functions and collates logging sent to it during the course of job runs. When jobs complete (either successfully or in error), logs are stored to metadata for later use. Storing log data to the database has its limitations (see TOAST and limits), but stays performant when used within reason.
Middleware installation
To use job-persisted logging, install riverlog.Middleware to River client:
riverClient, err := river.NewClient(riverpgxv5.New(dbPool), &river.Config{ Middleware: []rivertype.Middleware{ riverlog.NewMiddleware(func(w io.Writer) slog.Handler { return slog.NewJSONHandler(w, nil) }, nil), },})if err != nil { panic(err)}The middleware takes a function that initializes a slog logger to your specifications given an input writer. This writer maps to a buffer that riverlog uses to accumulate output for job runs before sending it to the database.
Logger in work context
With middleware installed, a logger is accessible in workers through riverlog.Logger(ctx):
import ( "context" "log/slog"
"github.com/riverqueue/river")type LoggingWorker struct { river.WorkerDefaults[LoggingArgs]}
func (w *LoggingWorker) Work(ctx context.Context, job *river.Job[LoggingArgs]) error { riverlog.Logger(ctx).Info("Logged from worker") riverlog.Logger(ctx).Info("Another line logged from worker", slog.String("key", "value")) return nil}Testing workers expecting logger
Use the rivertest.Worker test helpers configured with riverlog.Middleware to make a valid logger context available when testing workers:
import ( "github.com/riverqueue/river" "github.com/riverqueue/river/riverdriver/riverpgxv5" "github.com/riverqueue/river/riverlog" "github.com/riverqueue/river/rivertest" "github.com/riverqueue/river/rivertype")var ( config = &river.Config{ Middleware: []rivertype.Middleware{ riverlog.NewMiddleware(func(w io.Writer) slog.Handler { return slog.NewJSONHandler(w, nil) }, nil), }, } driver = riverpgxv5.New(nil) worker = &MyWorker{})testWorker := rivertest.NewWorker(t, driver, config, worker)In River UI
After being written to each job's row, logs are accessible from the job details page in River UI. Each run of a job shows up in its own section, complete with logs emitted during the run.
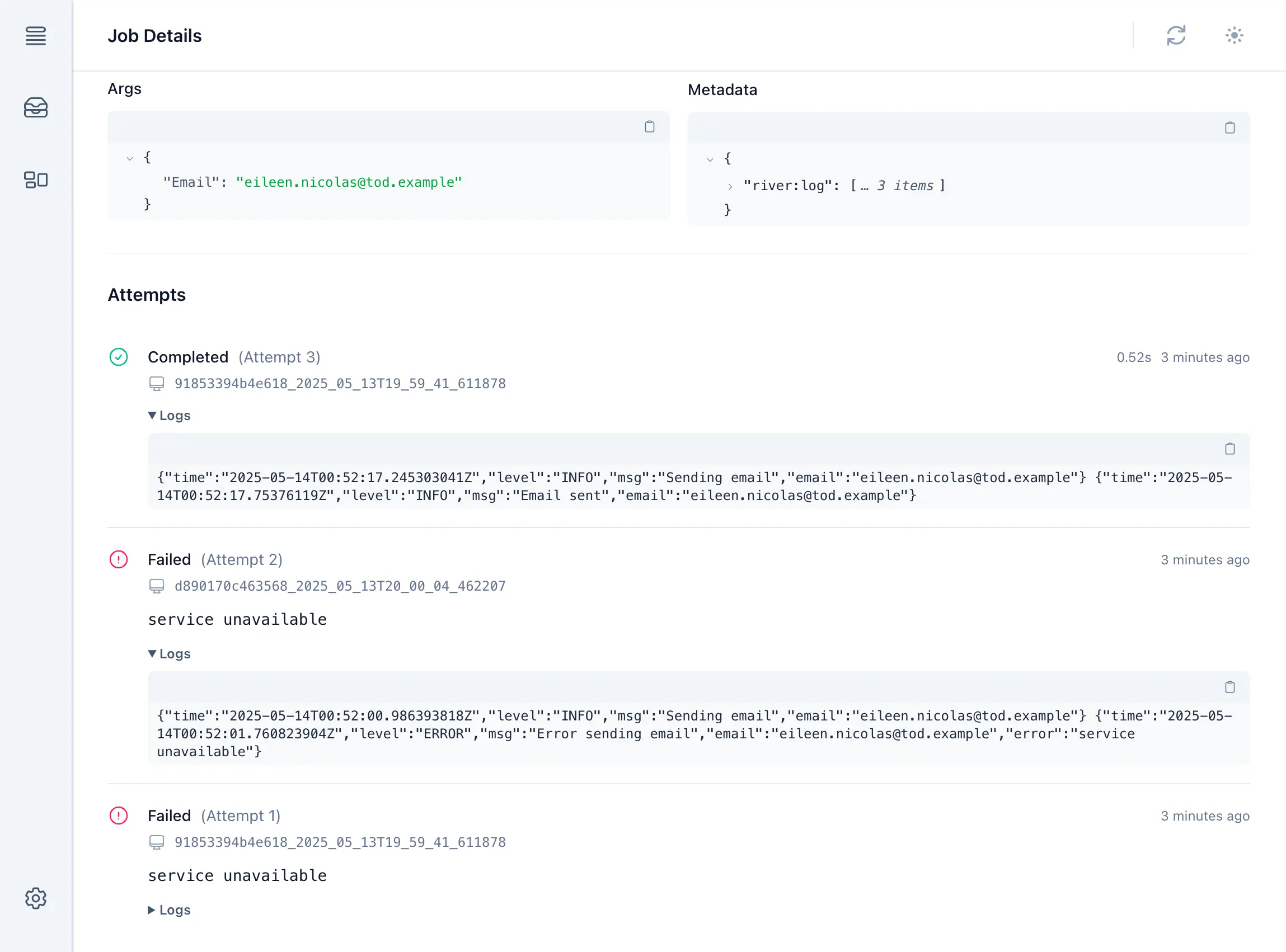
TOAST and limits
Job-persisted logs are stored to metadata. Metadata is a jsonb blob, making it a varlena type in Postgres that's stored out of band of its job row in TOAST, thereby having minimal impact on a job table's performance.
However, jsonb fields have a maximum size of 255 MB and because on the default retry policy a job will run up to 25 times, River caps the length of logs for a single run at 2 MB (2 * 25 = 50 MB, where 50 MB << 255 MB to leave room for other uses of metadata). This limit can be increased or decreased using the MiddlewareConfig.MaxSizeBytes option. It's not an error if logs exceed MaxSizeBytes, but they'll be truncated to fit.
Custom logging context
The default use of riverlog is tied quite strongly to Go's slog package, and although slog is a reasonable default in most situations, it might not be suitable for all projects.
For added flexibility riverlog provides an alternate NewMiddlewareCustomContext that takes a context and writer and returns a context that'll be inherited by Work functions. It can be used to store any arbitrary value to context like a Logrus or Zap logger:
type customContextKey struct{}
riverClient, err := river.NewClient(riverpgxv5.New(dbPool), &river.Config{ Middleware: []rivertype.Middleware{ riverlog.NewMiddlewareCustomContext(func(ctx context.Context, w io.Writer) context.Context { // For demonstration purposes we show the use of a built-in // non-slog logger, but this could be anything like Logrus or // Zap. Even the raw writer could be stored if so desired. logger := log.New(w, "", 0) return context.WithValue(ctx, customContextKey{}, logger) }, nil), },})if err != nil { panic(err)}func (w *CustomContextLoggingWorker) Work(ctx context.Context, job *river.Job[CustomContextLoggingArgs]) error { // Extract the logger embedded in context by middleware logger := ctx.Value(customContextKey{}).(*log.Logger) logger.Printf("Raw log from worker") return nil}